Run configurations¶
Run configurations are JSON, YAML or Excel files that contain specifications for how one or more Autory runs are to be performed. This is useful for when you need to perform many consecutive or simultaneous Autory runs.
Getting started¶
To get started, create a JSON, YAML or Excel template and modify its contents:
autory new run-config --type xl my-config
autory new run-config --type json my-config
autory new run-config --type yaml my-config
Understanding the JSON or YAML templates¶
The easiest way to understand the schema, is to look at the generated YAML template.
At the root, it contains two keys: common and runs. common contains default values for all runs in the
file. runs contains a list, where each list item represents a run. Values from runs take precedence over values
from common.
common:
a: b
c: d
runs:
- e: f
g: h
a: z
- e: i
g: j
c: y
The following keys may be used under common. More info about each one can be found in
the documentation for the autory run command. They are all optional.
modelnamesvisiblekeep_openenginesaverun_control
For each run, all the above keys may be used, plus an additional description key to distinguish the run from other
runs. Each run needs at least a model and a description. If you want to perform multiple runs from the same model,
the model may be specified under common and need not be repeated for each run.
For technical details on what can and cannot be put in these files, here is the full schema definition.
To learn how to read this schema, read the JSON Schema documentation.{
"$schema": "http://json-schema.org/draft-07/schema#",
"type": "object",
"properties": {
"common": {
"type": "object",
"properties": {
"model": {
"type": "string"
},
"names": {
"type": "object"
},
"visible": {
"type": "boolean"
},
"keep_open": {
"type": "boolean"
},
"engine": {
"type": "string"
},
"save": {
"type": "boolean"
},
"run_control": {
"type": "object"
},
"write_json": {
"type": "boolean"
},
"single_workbook": {
"type": "boolean"
}
},
"required": [],
"additionalProperties": false
},
"runs": {
"type": "array",
"items": {
"type": "object",
"properties": {
"model": {
"type": "string"
},
"names": {
"type": "object"
},
"visible": {
"type": "boolean"
},
"keep_open": {
"type": "boolean"
},
"engine": {
"type": "string"
},
"save": {
"type": "boolean"
},
"run_control": {
"type": "object"
},
"write_json": {
"type": "boolean"
},
"single_workbook": {
"type": "boolean"
},
"description": {
"type": "string"
}
},
"required": [],
"additionalProperties": false
}
}
},
"required": [
"common",
"runs"
],
"additionalProperties": false
}
Understanding the Excel template¶
The Excel template will look something like this:
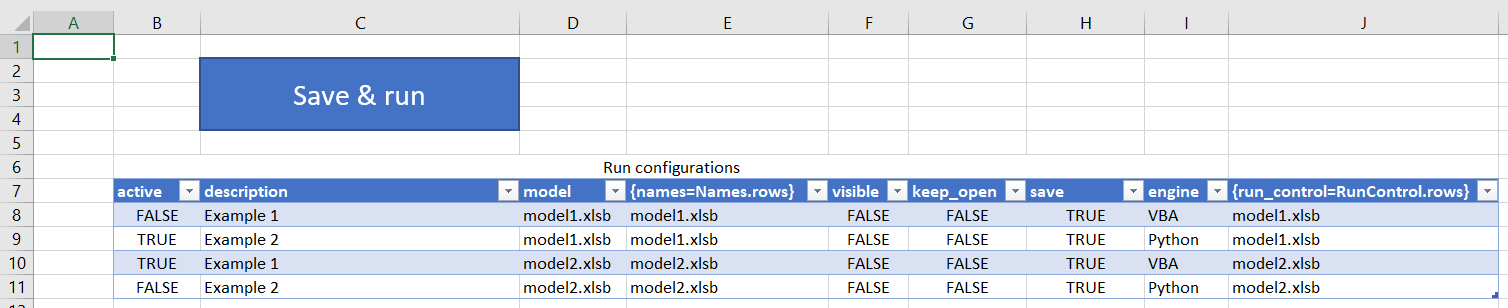
When you click Save & run, this template will be converted to a data structure like you see in
the JSON or YAML file, and then executed.
Each row represents a run. Rows with active=FALSE are ignored. There is no common section – if multiple runs use the
same values, simply copy the values down on the sheet.
The names and run_control columns are special. In these columns, we need to provide multiple key-value pairs for
each run, so they can't be represented on a single row in Excel. We solve this problem by splitting it to separate
tables. The column header defines how this works. For example, in {names=Names.rows}, the curly braces means that we
want to get some key-value pairs. names (before =) is the name of the column. Names (after =) is the name of the
table from which to grab the key-value pairs. .rows means that the rows of that table form the key-value pairs (rather
than the columns). The Names table might look like this:

The first column, called ID, is the lookup column. For each run, the value in the names column is looked up in
the ID column of the Names table, and the first matching row is used to construct key-value pairs. In this case, the
key-value pairs would be:
{
"output_folder": "%temp%",
"RunHierarchyLevel": 2,
"RunHierarchyPath": "A|B",
"RunStartValnType": "Summary"
}
This technique is called "table de-referencing". Here are more examples of what is possible in general:
| a | [b=Table2.rows] | {c=Table3} | [d] |
|---|---|---|---|
| 1 | foo | cols.bar | Table4.rows.baz |
| 2 | moo | rows.oink | Table5.cols.bork |
ais a normal column.[b=Table2.rows]: The column name is b. Each cell in this column contains an array of values taken from a row in Table2.{c=Table3}: The column name is c. Each cell in this column contains an object of values taken from Table3. The values may come from a column (with the ID column used for keys) or from a row (with the header used for keys).[d]: The column name is d. Each cell in this column contains an array. It can reference rows or columns in any table.